CUDA从0开始
前言
为了ASC!为了速度!
统一计算设备架构(Compute Unified Device Architecture, CUDA),是由NVIDIA推出的通用并行计算架构。解决的是用更加廉价的设备资源,实现更高效的并行计算。
参考资料见ASC22备赛博客文章CUDA部分。
一、异构并行计算
先简要介绍了使用GPU来完善CPU的异构架构,以及向异构并行编程进行的模式转变

上面这张图能大致反应CPU和GPU的架构不同。
- 左图:一个四核CPU一般有四个ALU,ALU是完成逻辑计算的核心,也是我们平时说四核八核的核,控制单元,缓存也在片上,DRAM是内存,一般不在片上,CPU通过总线访问内存。
- 右图:GPU,绿色小方块是ALU,我们注意红色框内的部分SM,这一组ALU公用一个Control单元和Cache,这个部分相当于一个完整的多核CPU,但是不同的是ALU多了,control部分变小,可见计算能力提升了,控制能力减弱了,所以对于控制(逻辑)复杂的程序,一个GPU的SM是没办法和CPU比较的,但是对了逻辑简单,数据量大的任务,GPU更搞笑,并且,注意,一个GPU有好多个SM,而且越来越多。
SP和SM(流处理器)
SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。需要指出,每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个
简而言之,SP是线程执行的硬件单位,SM中包含多个SP,一个GPU可以有多个SM(比如16个),最终一个GPU可能包含有上千个SP。这么多核心“同时运行”,速度可想而知,这个引号只是想表明实际上,软件逻辑上是所有SP是并行的,但是物理上并不是所有SP都能同时执行计算(比如我们只有8个SM却有1024个线程块需要调度处理),因为有些会处于挂起,就绪等其他状态,这有关GPU的线程调度。
CPU和GPU之间通过PCIe总线连接,用于传递指令和数据,这部分也是后面要讨论的性能瓶颈之一。
一个异构应用包含两种以上架构,所以代码也包括不止一部分:
- 主机代码
- 设备代码
主机代码在主机端运行,被编译成主机架构的机器码,设备端的在设备上执行,被编译成设备架构的机器码,所以主机端的机器码和设备端的机器码是隔离的,自己执行自己的,没办法交换执行。
主机端代码主要是控制设备,完成数据传输等控制类工作,设备端主要的任务就是计算。
因为当没有GPU的时候CPU也能完成这些计算,只是速度会慢很多,所以可以把GPU看成CPU的一个加速设备。
NVIDIA目前的计算平台(不是架构)有:
- Tegra
- Geforce
- Quadro
- Tesla
每个平台针对不同的应用场景,比如Tegra用于嵌入式,Geforce是我们平时打游戏用到,Tesla是我们昨天租的那台腾讯云的,主要用于计算。
衡量GPU计算能力的主要靠下面两种容量\特征:
- CUDA核心数量(越多越好)
- 内存大小(越大越好)
相应的也有计算能力的性能\指标:
- 峰值计算能力
- 内存带宽
nvidia自己有一套描述GPU计算能力的代码,其名字就是“计算能力”,主要区分不同的架构,早其架构的计算能力不一定比新架构的计算能力强
| 计算能力 | 架构名 |
|---|---|
| 1.x | Tesla |
| 2.x | Fermi |
| 3.x | Kepler |
| 4.x | Maxwell |
| 5.x | Pascal |
| 6.x | Volta |
CPU和GPU线程的区别:
- CPU线程是重量级实体,操作系统交替执行线程,线程上下文切换花销很大
- GPU线程是轻量级的,GPU应用一般包含成千上万的线程,多数在排队状态,线程之间切换基本没有开销。
- CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU核则是大量线程,最大幅度提高吞吐量
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持

CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端代码,而且CUDA库本身提供了大量API来操作设备完成计算。
对于API也有两种不同的层次,一种相对交高层,一种相对底层。
- CUDA驱动API
- CUDA运行时API
驱动API是低级的API,使用相对困难,运行时API是高级API使用简单,其实现基于驱动API。
这两种API是互斥的,也就是你只能用一个,两者之间的函数不可以混合调用,只能用其中的一个库。
一个CUDA应用通常可以分解为两部分,
- CPU 主机端代码
- GPU 设备端代码
CUDA nvcc编译器会自动分离你代码里面的不同部分,如图中主机代码用C写成,使用本地的C语言编译器编译,设备端代码,也就是核函数,用CUDA C编写,通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
注意:核函数是我们后面主要接触的一段代码,就是设备上执行的程序段
“Hello World!”
Hello World是所有程序初学者都非常喜欢的,之前GPU是不能printf的,我当时就很懵,GPU是个做显示的设备,为啥不能输出,后来就可以直接在CUDA核里面打印信息了,我们写下面程序
/*
*hello_world.cu
*/
#include<stdio.h>
__global__ void hello_world(void)
{
printf("GPU: Hello world!\n");
}
int main(int argc,char **argv)
{
printf("CPU: Hello world!\n");
hello_world<<<1,10>>>();
cudaDeviceReset();//if no this line ,it can not output hello world from gpu
return 0;
}一般CUDA程序分成下面这些步骤:
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核函数来执行计算
- 把计算完成数据拷贝回主机端
- 内存销毁
CPU与GPU的编程主要区别在于对GPU架构的熟悉程度,理解机器的结构是对编程效率影响非常大的一部分,了解你的机器,才能写出更优美的代码,而目前计算设备的架构决定了局部性将会严重影响效率。
数据局部性分两种
- 空间局部性
- 时间局部性
CUDA中有两个模型是决定性能的:
- 内存层次结构
- 线程层次结构
CUDA C写核函数的时候我们只写一小段串行代码,但是这段代码被成千上万的线程执行,所有线程执行的代码都是相同的,CUDA编程模型提供了一个层次化的组织线程,直接影响GPU上的执行顺序。
CUDA抽象了硬件实现:
- 线程组的层次结构
- 内存的层次结构
- 障碍同步
这些都是我们后面要研究的,线程,内存是主要研究的对象,我们能用到的工具相当丰富,NVIDIA为我们提供了:
- Nvidia Nsight集成开发环境
- CUDA-GDB 命令行调试器
- 性能分析可视化工具
- CUDA-MEMCHECK工具
- GPU设备管理工具
二、CUDA编程模型
从逻辑视角解释了在CUDA中的大规模并行计算:通过编程模型直观展示的两层线程层次结构。同时也探讨了线程配置启发性方法和它们对性能的影响。
CUDA编程模型为应用和硬件设备之间的桥梁,所以CUDA C是编译型语言,不是解释型语言,OpenCL就有点类似于解释型语言,通过编译器和链接,给操作系统执行(操作系统包括GPU在内的系统),下面的结构图片能形象的表现他们之间的关系:
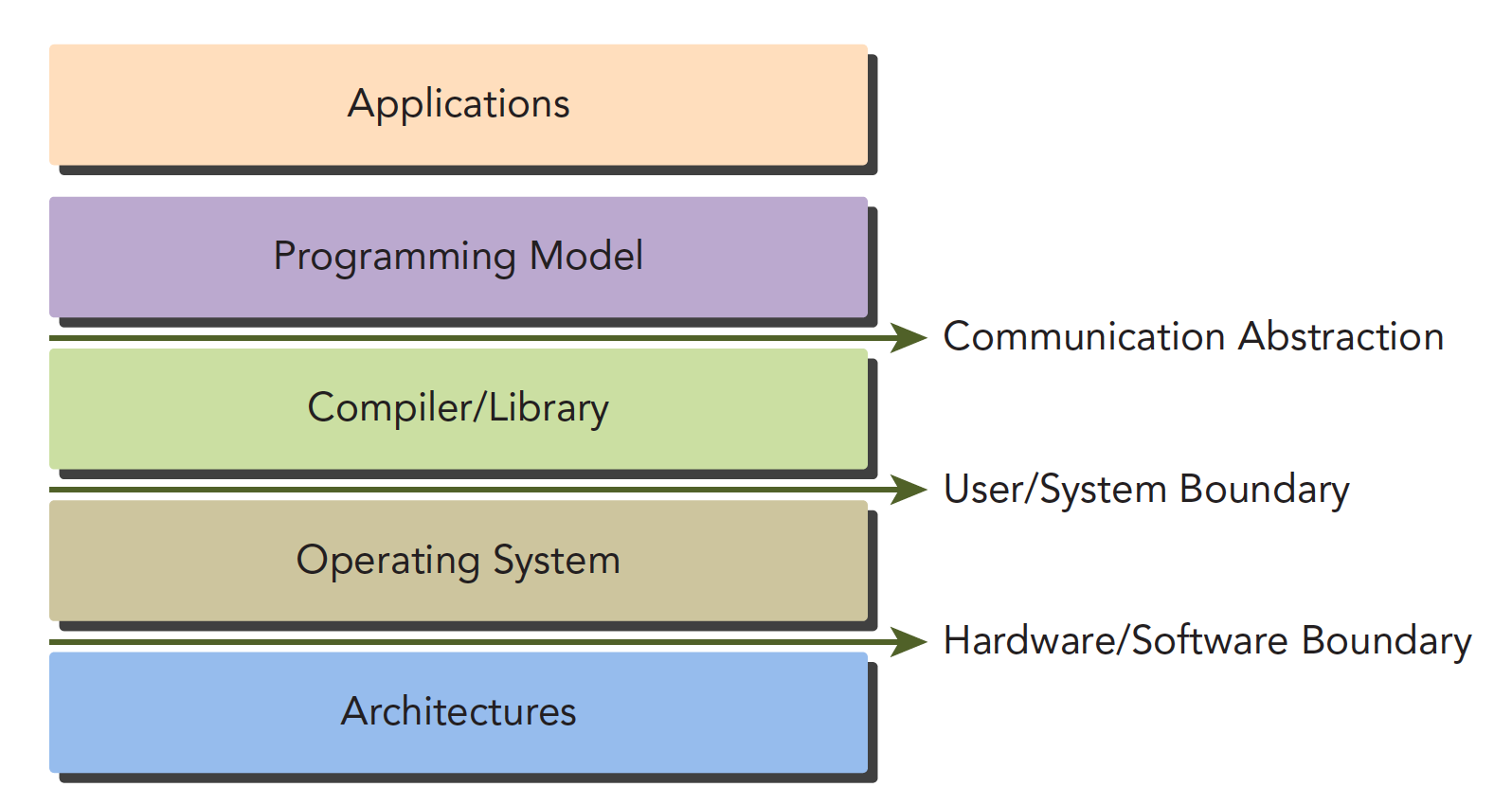
其中Communication Abstraction是编程模型和编译器,库函数之间的分界线。
可能大家还不太明白编程模型是啥,编程模型可以理解为,我们要用到的语法,内存结构,线程结构等这些我们写程序时我们自己控制的部分,这些部分控制了异构计算设备的工作模式,都是属于编程模型。
GPU中大致可以分为:
- 核函数
- 内存管理
- 线程管理
- 流
等几个关键部分。
以上这些理论同时也适用于其他非CPU+GPU异构的组合。
下面我们会说两个我们GPU架构下特有几个功能:
- 通过组织层次结构在GPU上组织线程的方法
- 通过组织层次结构在GPU上组织内存的方法
也就是对内存和线程的控制将伴随我们写完前十几篇。
从宏观上我们可以从以下几个环节完成CUDA应用开发:
- 领域层
- 逻辑层
- 硬件层
三、CUDA执行模型
研究成千上万的线程是如何在GPU中调度的,来探讨硬件层面的内核执行问 题。解释了计算资源是如何在多粒度线程间分配的,也从硬件视角说明了它如何被用于指导内核设计,以及如何用配置文件驱动方法来开发和优化内核程序。
一个异构环境,通常有多个CPU多个GPU,他们都通过PCIe总线相互通信,也是通过PCIe总线分隔开的。所以我们要区分一下两种设备的内存:
- 主机:CPU及其内存
- 设备:GPU及其内存
注意这两个内存从硬件到软件都是隔离的(CUDA6.0 以后支持统一寻址),我们目前先不研究统一寻址,我们现在还是用内存来回拷贝的方法来编写调试程序,以巩固大家对两个内存隔离这个事实的理解。
一个完整的CUDA应用可能的执行顺序如下图: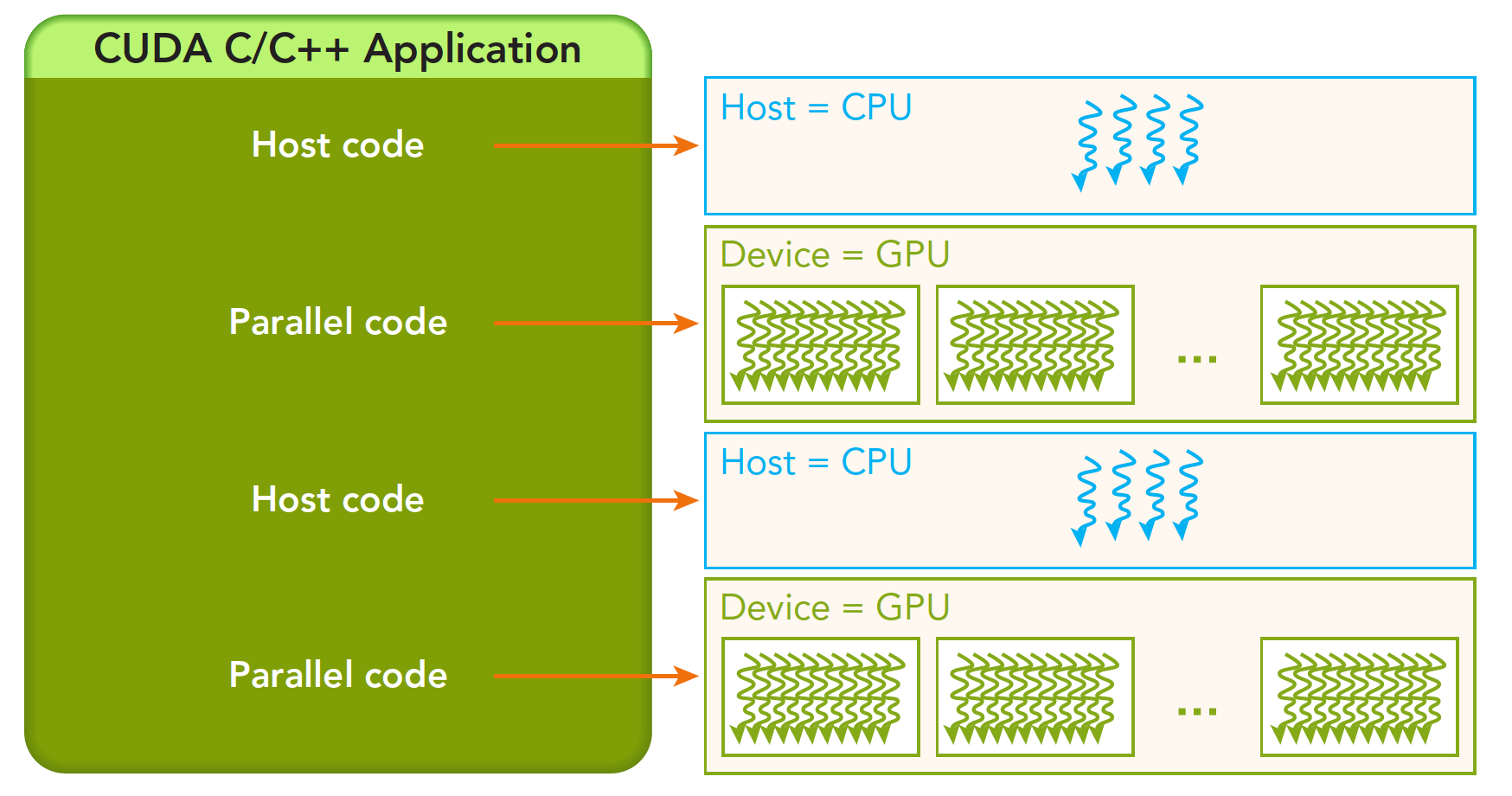
从host的串行到调用核函数(核函数被调用后控制马上归还主机线程,也就是在第一个并行代码执行时,很有可能第二段host代码已经开始同步执行了)。
我们接下来的研究层次是:
内存
线程
核函数
- 启动核函数
- 编写核函数
- 验证核函数
错误处理
内存管理
内存管理在传统串行程序是非常常见的,寄存器空间,栈空间内的内存由机器自己管理,堆空间由用户控制分配和释放,CUDA程序同样,只是CUDA提供的API可以分配管理设备上的内存,当然也可以用CDUA管理主机上的内存,主机上的传统标准库也能完成主机内存管理。
下面表格有一些主机API和CUDA C的API的对比:
| 标准C函数 | CUDA C 函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
我们先研究最关键的一步,这一步要走总线的(郭德纲:我到底能不能走二环)
cudaError_t cudaMemcpy(void * dst,const void * src,size_t count,
cudaMemcpyKind kind)这个函数是内存拷贝过程,可以完成以下几种过程(cudaMemcpyKind kind)
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这四个过程的方向可以清楚的从字面上看出来,这里就不废话了,如果函数执行成功,则会返回 cudaSuccess 否则返回 cudaErrorMemoryAllocation
使用下面这个指令可以吧上面的错误代码翻译成详细信息:
char* cudaGetErrorString(cudaError_t error)共享内存(shared Memory)和全局内存(global Memory)后面我们会特别详细深入的研究,这里我们来个例子,两个向量的加法:
解释下内存管理部分的代码:
cudaMalloc((float**)&a_d,nByte);分配设备端的内存空间,为了区分设备和主机端内存,我们可以给变量加后缀或者前缀h_表示host,d_表示device
一个经常会发生的错误就是混用设备和主机的内存地址!
线程管理
当内核函数开始执行,如何组织GPU的线程就变成了最主要的问题了,我们必须明确,一个核函数只能有一个grid,一个grid可以有很多个块,每个块可以有很多的线程,这种分层的组织结构使得我们的并行过程更加自如灵活:
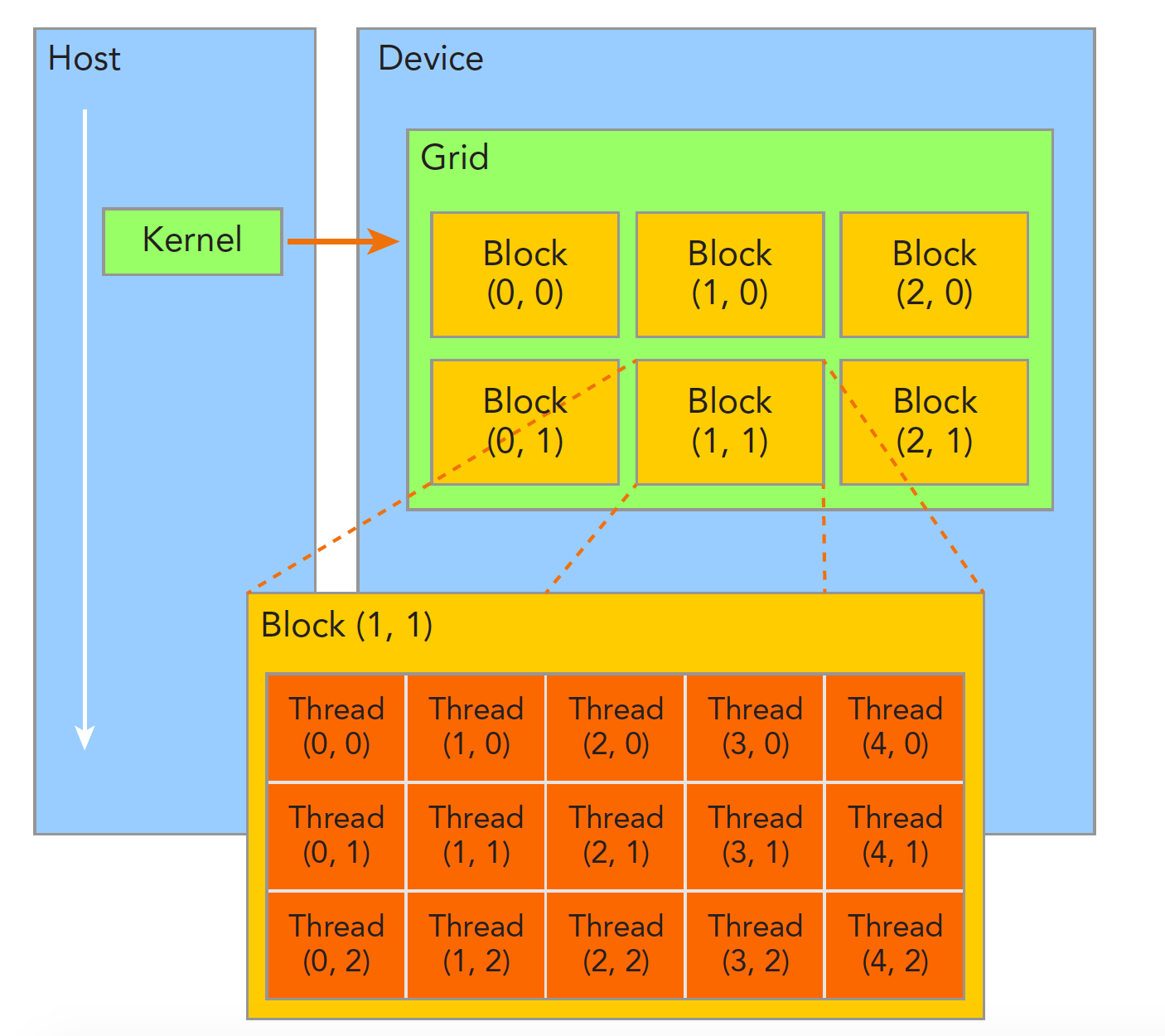
一个线程块block中的线程可以完成下述协作:
- 同步
- 共享内存
不同块内线程不能相互影响!他们是物理隔离的!
接下来就是给每个线程一个编号了,我们知道每个线程都执行同样的一段串行代码,那么怎么让这段相同的代码对应不同的数据呢?首先第一步就是让这些线程彼此区分开,才能对应到相应从线程,使得这些线程也能区分自己的数据。如果线程本身没有任何标记,那么没办法确认其行为。
依靠下面两个内置结构体确定线程标号:
- blockIdx(线程块在线程网格内的位置索引)
- threadIdx(线程在线程块内的位置索引)
注意这里的Idx是index的缩写(我之前一直以为是identity x的缩写),这两个内置结构体基于 uint3 定义,包含三个无符号整数的结构,通过三个字段来指定:
- blockIdx.x
- blockIdx.y
- blockIdx.z
- threadIdx.x
- threadIdx.y
- threadIdx.z
上面这两个是坐标,当然我们要有同样对应的两个结构体来保存其范围,也就是blockIdx中三个字段的范围threadIdx中三个字段的范围:
- blockDim
- gridDim
他们是dim3类型(基于uint3定义的数据结构)的变量,也包含三个字段x,y,z.
- blockDim.x
- blockDim.y
- blockDim.z
注意:dim3是手工定义的,主机端可见。uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了。他们是有区别的!这一点必须要注意。
下面有一段代码,块的索引和维度:
四、内存
CUDA内存模型,探讨全局内存数据布局,并分析了全局内存的访问模式。共享内存,即管理程序的低延迟缓存,是如何提高内核性能的。它描述了共享内存的优化数据布局,并说明了如何避免较差的性能。最后还说明了如何在相邻线程之间执行低延迟通信。
五、流和并发
如何使用CUDA流实现多内核并发执行,如何重叠通信和计算,以及不同的任务分配策略是如何影响内核间的并发的。
六、指令级原语
本章解释了浮点运算、标准的内部数学函数和CUDA原子操作的性质。它展示了如何使用相对低级别的CUDA原语和编译器标志来优化应用程序的性能、准确度和正确性。
七、GPU加速库和OpenACC
程序并行的CUDA专用函数库,包括线性代数、傅里叶变换和随机数 生成等范例。本章还解释了OpenACC和基于编译器指令的GPU编程模型是如何利用更简单 的方法辅助CUDA挖掘GPU计算能力的。
八、多GPU编程
阐述了如何在多个GPU上管理和执行计算问题,还说明了在GPU加速计算集群上的大规模应用是如何利用MPI与GPUDirectRDMA来实现性能线性扩展的。
九、程序实现注意事项
本章介绍了CUDA的开发过程和各种配置文件驱动的优化策略,演示了如何使用CUDA调试工具来调试内核和内存错误,通过案例教你如何将一个传统的C程序一步步移植到CUDA C中,以有助于加强你对于这一方法的理解,同时将此过程可视化,并验证了这些工具。
trick
cmake和cuda万能模板
# CMakeLists.txt for test -x cu option project by guan shiyuan
project(test_cuda_project)
# required cmake version
cmake_minimum_required(VERSION 2.8)
# packages
find_package(CUDA)
set(CUDA_SOURCE_PROPERTY_FORMAT OBJ)
set(CUDA_SEPARABLE_COMPILATION ON)
include_directories(${CUDA_INCLUDE_DIRS})
set(CUDA_PROPAGATE_HOST_FLAGS OFF)
set(CUDA_NVCC_FLAGS -arch=sm_61;-O3;-G;-g;-std=c++11)
file(GLOB_RECURSE CURRENT_HEADERS *.h *.hpp *.cuh)
file(GLOB CURRENT_SOURCES *.cpp *.cu)
set_source_files_properties(main.cpp PROPERTIES CUDA_SOURCE_PROPERTY_FORMAT OBJ)
source_group("Include" FILES ${CURRENT_HEADERS})
source_group("Source" FILES ${CURRENT_SOURCES})
cuda_add_executable(test_cuda_project ${CURRENT_HEADERS} ${CURRENT_SOURCES} )


